
IAGen, « on n’a rien sans rien »
-
 Antoine de Véricourt
Antoine de Véricourt
Depuis 1 an, les anticipations stratégiques, les questions d’éthiques et parfois même philosophiques ont accompagné le choc de l’IA Générative démocratisée. Certes, la peinture n’est pas encore sèche sur de nombreux sujets de gouvernance à bien des niveaux (y compris chez OPEN AI…).
Le cadre réglementaire est encore flou et même parfois contradictoire (US vs EUR). Par ailleurs, l’adoption de l’IA Générative par les entreprises est hétérogène (certaines en permettent l’usage, d’autres pas du tout). Côté produit, les biais algorithmiques existent toujours (hallucinations minimes, graves erreurs computationnelles).
Et alors ? L’heure est à l’action concrète et la mesure du ROI (positif ou négatif)
Un déploiement opérationnel de l’IA Générative encore timide mais en progression
L’objectif est simple, tirer rapidement le meilleur parti de cette technologie ou passer à autre chose. Les communications sur le nombre de cas d’usages identifiés sont pléthores et font parfois l’objet d’une surenchère grotesque. Comme l’évoque le Gartner*, l’effet de sidération est passé, place à l’appropriation.
Reconnaissons-le, déployer concrètement une IA Générative en entreprise peut relever du parcours du combattant. Par conséquent les cas concrets d’application opérationnelle de l’IA Générative sont encore très peu nombreux.
Certaines entreprises s’organisent mieux que d’autres pour maîtriser ces technologies. Leur appropriation passe notamment par le partage d’expériences acquises sur le terrain. C’est ce que font les équipes d’Okuden très sollicitées dans ce domaine.
1. Les défis du déploiement en entreprise…
Avez-vous essayé d’utiliser l’IA Générative pour traiter un cas opérationnel concret dans votre entreprise ? D’obscures forces, réglementaires, opérationnelles, techniques et parfois managériales se sont sans-doute manifestées pour vous décourager.
Vous avez peut-être fini par rencontrer de bonnes âmes pour ayant géré en amont les problématiques d’infrastructure, d’accès aux outils et de protection de données. Celles-ci se sont par ailleurs occupées à signer des contrats cadre pour mettre à votre disposition un ou plusieurs moteurs d’IA Générative.
Là tout n’est qu’ordre et beauté, luxe, calme et connectivité…Vous pouvez commencer.
2. Une approche mutualisable des cas d'usage
Quelle est le point commun entre les cas d’usage suivants ?
- Catégorisation des retours clients pour le marketing ou gestion de leads
- Assistance commerciale pour des clients de l’assurance
- Amélioration du parcours client de solutions de mobilité en LLD
- Support avant-vente chez un Asset Servicer
- Exégèse réglementaire dans le milieu bancaire (documentation ACPR, BCE…)
- Maintenance préventive dans le domaine du transport maritime
L’expérience acquise fait émerger un besoin identique d’exploitation de bases de connaissances complexes. Du Front au Back en passant par les fonctions régaliennes de la Gestion des Risques ou de la Finance, les « knowledge base » sont nécessaires dans tous les cas. Les problématiques opérationnelles et techniques sont similaires et les capacités mutualisables dans certains cas.
Partageons quelques retours d’expérience sur le sujet.
3. La vectorisation, une fonctionnalité devenue naturelle
Hier, il fallait empiler plusieurs couches techniques pour vectoriser « embedder » des données opérationnelles afin de les rendre exploitables par un modèle d’IA Générative (par exemple : retours clients, textes réglementaires…).
C’était sans compter le coût non maîtrisé de l’opération in fine et les limites techniques de chargement (token).
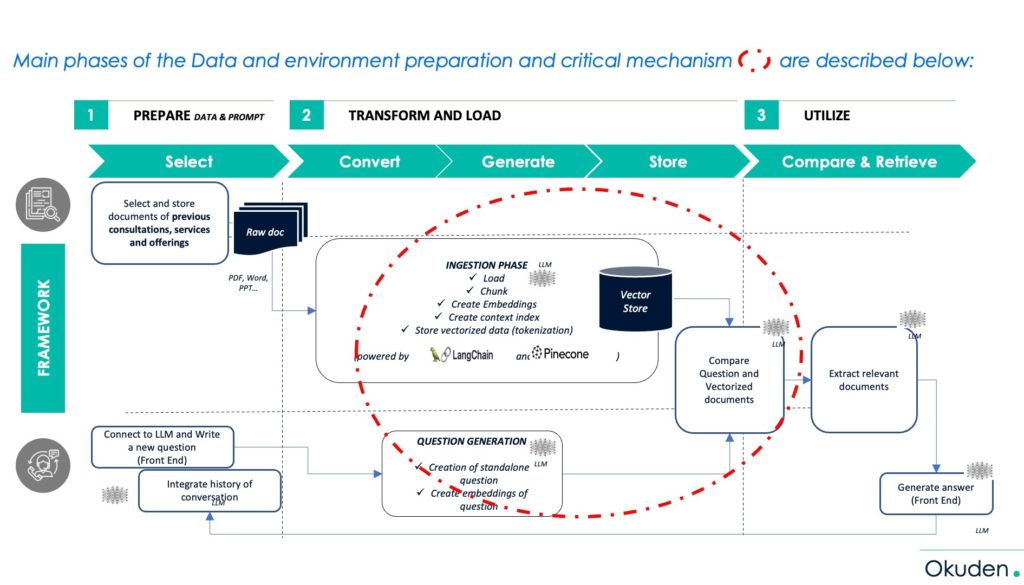
Depuis la semaine dernière, OPEN AI GPT4 – TURBO a intégré cette fonctionnalité dans son API. Vous pouvez charger des fichiers avec une facilité déconcertante.
Le volume de données chargeable ne fait que croitre (contexte initialement capé à 8k multiplié par 16**). Au-delà des capacités, il est donc beaucoup plus facile de lier des fichiers au modèle. Le gros problème réside encore dans la transparence de traitement, la confidentialité du stockage et le coût à l’échelle.
La valeur attendue sur les cas d’usages est-elle alors garantie ? acquise ? Non, il faut aller plus loin.
Les transformations digitales que nous accompagnons chez Okuden sont vastes, complexes et à forts niveaux d’enjeux business pour nos clients. Celles-ci ne se limitent pas à une question de chargement. La réalité est qu’entre l’idée du cas d’usage et la pratique, il y a un écart à mesurer, maîtriser.
4. Les LLM savent rédiger, synthétiser et presque raisonner… Tout est dans le "presque".
Tel un enfant lançant un avion en papier depuis le balcon, il est jubilatoire de « lancer » un LLM (Large Model Language) dans une base de connaissances opérationnelles.
Des réponses contextualisées vont fuser, mais ont-elles suffisamment de sens et de qualité pour le métier impliqué ou le client concerné ?
Dans le domaine de la gestion du risque de crédit, vous pouvez obtenir des éléments contradictoires d’importance capitale dans une réponse parfaitement rédigée. Par exemple lors d’un exercice d’interprétation des règles prudentielles sur le traitement de contreparties formellement en défaut, le LLM associe dans sa réponse une probabilité de défaut de 5%. Lui faisant remarquer son erreur, le modèle présente ses excuses.
Cet exemple n’a pas vocation à décrédibiliser la technologie mais à prendre la mesure de ce qui vous attend pour tirer la pleine valeur de vos cas d’usage, notamment les plus complexes. En matière d’IA Générative, le dernier kilomètre est le plus difficile à franchir.
5. Oui, l’apprentissage renforcée demande de l’effort…
Artificielle ou pas et quelque soit l’éditeur, l’intelligence du LLM portée par son modèle reste à entrainer, re-entrainer, voire à dresser. Très concrètement, le traitement d’un cas d’usage sur des fonctions de catégorisation a nécessité pour nos équipes :
- De nombreux tests initiaux avec les modèles de complétion génériques en faisant varier le degré de créativité/liberté (température)
- Des ajustements en termes d’instructions (prompt) afin d’optimiser au mieux les résultats
- La constitution d’un échantillon d’exemples (séries de données)
- La création d’un modèle optimisé (fine-tuné) sur la base des exemples constitués
- L’analyse des performances du modèle
Conclusion : Du rêve à la réalité
Des tâches à faible valeur ajoutée peuvent être couvertes par un LLM posant ainsi la question du surdimensionnement ? Le volume et la fréquence des tâches sont des facteurs favorisant leur adoption (“mass market fund classification” par exemple).
Par ailleurs, pour des tâches à forte valeur ajoutée, le maintien d’expertises semble inéluctable, celles-ci permettant de garantir la cohérence et l’employabilité des résultats (interprétation réglementaire, réponses à appel d’offres, closing client…).
Générer des gains grâce aux LLMs n’est donc pas trivial, seule l’expérimentation concrète fait progresser.
Les cas d’usage doivent donc être testés très concrètement afin :
- D’éviter de générer plus de coûts qu’en situation initiale (3),
- De sécuriser la valeur attendue même si celle-ci sera capée (2),
- D’éviter de poursuivre le miroir aux alouettes (1)
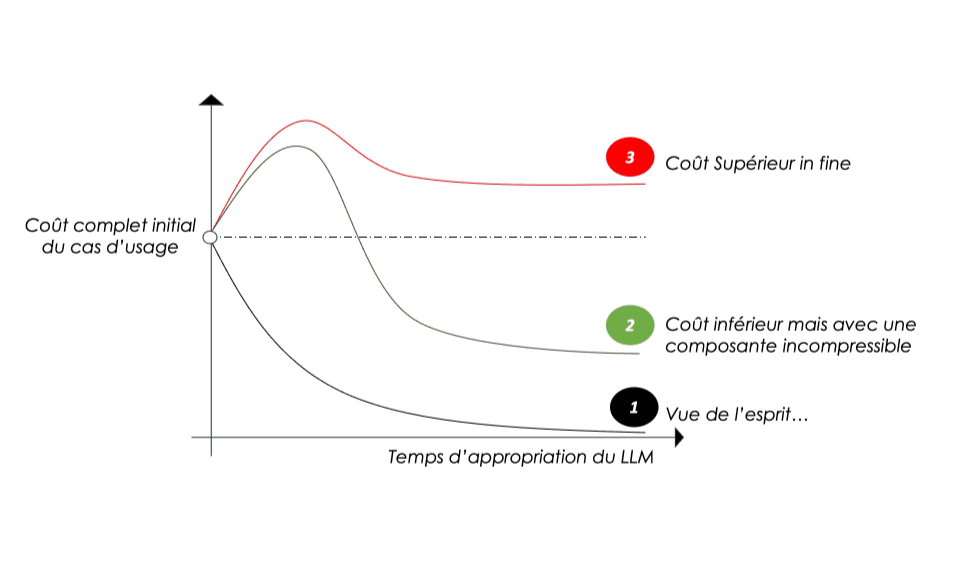
Au-delà des anticipations stratégiques et hypothétiques, lancez-vous pour transformer le ROI rêvé en realité tangible. A vous de jouer !
Sources :
*https://www.linkedin.com/posts/gartner_gartnerit-cio-itspending-activity-7132436839520456704-fdTA?utm_source=share&utm_medium=member_desktop
** https://www.youtube.com/watch?v=U9mJuUkhUzk
Okuden accompagne les grands groupes dans leurs transformations digitales. Optant pour une approche innovante et résolument sectorielle, les équipes d’Okuden sont spécialistes de la banque et de l’assurance, de l’automobile et de la mobilité, des médias et du gaming.
Prenez rendez-vous avec un de nos experts.

